Many strongly typed languages like OCaml do type inference. That is, even though they’re strongly typed, you don’t have to explicitly say what the type of everything is since a lot of the time the compiler can figure it out by itself. For example, if you define a function which takes an x and adds it to 3, the compiler will figure out that x is an int. (It couldn’t be a float, since it was added to 3 and not 3.0.)
But it often seems like the compiler should be able to infer not just the types of expressions, but the expressions themselves! For example, if the compiler infers that the type of some function f is (int -> int) -> (int list) -> int list (i.e., f is a higher-order function which takes a function from int to int, a list of ints, and produces a list of ints), then f is very probably the map function, defined informally by
map g [x_1;...;x_n] = [g x_1;...;g x_n].
Therefore, if the compiler determines that some expression has that type, and the user has somehow omitted the actual function definition, why not allow the compiler to infer what the expression is?
I made a stab at implementing this type of idea in a toy language I call TermInf (apologies for the weird hosting: I don’t have another hosting service at the moment). It’s a modification of the toy language Poly from Andrej Bauer’s Programming Language Zoo. You’ll need OCaml to compile it. Please feel free to alert me to any bugs or to tell me that my code is horrible.
More details below.
The basic idea is really simple: For any expression e, the expression {e} is also an expression. The compiler will infer the type t1 of e and the type t2 that {e} has to be. It will search for a sequence of coercions taking t1 to t2 and if there is a unique one, it will replace {e} with that sequence of coercions applied to e.
Which functions are coercions is determined by the user; functions can be declared to be coercions or removed from the list of coercions at any point.
I can think of at least three ways this would be useful.
1. Automatically coercing from one base type to another
This is actually the least interesting of the three, but it serves to illustrate how TermInf works.
You can use $show_coercions to show all the current coercions. The identity
function id is always a coercion.
TermInf. Press Ctrl-D to exit. TermInf> $show_coercions id
Let’s define a new coercion from bool to int.
TermInf> let_coercion bool_to_int = fun x -> if x then 1 else 0 val bool_to_int : bool -> int TermInf> $show_coercions bool_to_int id
Now we can use the coercion.
TermInf> {true} + 7
- : int = 8
In that instance, the interpreter could determine that the type of {true} had to be int, since it was added to 7. In the following instance, the interpreter can’t determine type of {true}.
TermInf> {true}
Problem with term inference.
But we can always explicitly give a type to any expression, so we can use that to tell the type-inferer what the type of {true} is.
TermInf> {true} : bool
- : bool = true
TermInf> {true} : int
- : int = 1
2. Lifting functions
We can view the function List.map as a coercion, taking a function 'a -> 'b to a function 'a list -> 'b list.
TermInf> let_coercion map = rec map is fun f -> fun l -> match l with [] -> [] | x::ll -> (f x)::(map f ll)
val map : ('a -> 'b) -> 'a list -> 'b list
TermInf> $show_coercions
map
bool_to_int
id
Now we can try it out.
TermInf> let square = fun x -> x * x
val square : int -> int
TermInf> ({square} 3) : int
- : int = 9
TermInf> ({square} [1;2;3]) : int list
- : int list = 1 :: 4 :: 9 :: []
TermInf> ({square} [[1;2];[5;6;7]]) : int list list
- : (int list) list = (1 :: 4 :: []) :: (25 :: 36 :: 49 :: []) :: []
Note that in our case, we had to explicitly tell the interpreter what the return type was, although presumably in practice the interpreter or compiler would usually be able to infer it.
The idea is that we can change the basic structure of the thing passed to {square}, and the term inferer will adapt. Note that in the third case, the term inferer iterated map to produce the required (int list list -> int list list) type.
We can similarly look inside the structure of pairs.
TermInf> let_coercion map_pair = fun f -> fun x -> (f (fst x), f (snd x))
val map_pair : ('a -> 'b) -> 'a * 'a -> 'b * 'b
TermInf> ({square} [(1,2);(3,4)]) : (int * int) list
- : (int * int) list = (1, 4) :: (9, 16) :: []
TermInf> ({square} ([1;2],[3;4])) : (int list) * (int list)
- : int list * int list = (1 :: 4 :: [], 9 :: 16 :: [])
Essentially all variants of map can be added. For example, the function mapi : ((int * 'a) -> 'b) -> 'a list -> 'b list where the function takes the index of the list element can be added. Then the term-inferer will determine which version of map (or sequence of versions of map) is needed based on the function given to it.
3. Term inference in conjunction with phantom types.
I put just enough type aliasing in TermInf to allow you to use phantom types. (For a great introduction to phantom types, see this blog post).
Here’s an example of how type aliasing works in TermInf:
TermInf> type hidden = int TermInf> let f = (fun x -> x + 7) : hidden -> hidden val f : hidden -> hidden TermInf> let x = 3 : hidden val x : hidden TermInf> f x - : hidden = 10 TermInf> f 3 The types hidden and int are incompatible
Something we might like to do with phantom types is have the type system do a static dimensional analysis on our program. Here’s an attempt to do that:
TermInf> type meters
TermInf> type gallons
TermInf> type 'a units = int
TermInf> let add = (fun x -> fun y -> x + y) : 'a units -> 'a units -> 'a units
val add : 'a units -> 'a units -> 'a units
TermInf> let times = (fun x -> fun y -> x * y) : 'a units -> 'b units -> ('a * 'b) units
val times : 'a units -> 'b units -> ('a * 'b) units
TermInf> let one_gal = 1 : gallons units
val one_gal : gallons units
TermInf> let one_m = 1 : meters units
val one_m : meters units
Then we have the following correct behavior:
TermInf> add one_gal one_gal - : gallons units = 2 TermInf> times one_gal one_m - : (gallons * meters) units = 1 TermInf> add one_gal one_m The types gallons and meters are incompatible
But the following is not correct:
TermInf> let x = times one_gal one_m val x : (gallons * meters) units TermInf> let y = times one_m one_gal val y : (meters * gallons) units TermInf> add x y The types gallons and meters are incompatible
Of course, the problem is that the interpreter doesn’t know that units commute.
But we can fix this with coercions.
TermInf> let_id_coercion commute = id : ('a * 'b) units -> ('b * 'a) units
val commute : ('a * 'b) units -> ('b * 'a) units
TermInf> add x {y}
- : (gallons * meters) units = 2
We’ve declared commute to be an identity coercion (by using let_id_coercion instead of let_coercion) to help the interpreter when it’s deciding if a term inference is unique or not.
Note that we don’t use term inference on both x and y, because then it couldn’t determine what type to give it.
TermInf> add {x} y
- : (meters * gallons) units = 2
TermInf> add {x} {y}
Problem with term inference.
This version of commute will just commute the two units at the top level, but there are a finite number of identity coercions that you can define that will give you associativity and commutativity (and inverses, if you want). Thus, the type system will be able to perform a static dimensional analysis on your program.
Edit: I should note that I left out several details about how this actually works. For example, the interpreter doesn’t search through all sequences of coercions, since there are infinitely many (and the problem of deciding if there is a unique one between any two given types is undecidable in general). Instead it limits itself to sequences of coercions whose type is never “bigger” that the starting type or the goal type, where “bigger” is defined by a straightforward length function.

Using the Curry-Howard correspondence we see that what you are doing is automated theorem proving for (intuitionistic) propositional calculus. That is, the type is a statement which you want to prove, and the term is the proof you are looking for. Proofs in intuitionistic propositional calculus have normal forms, so you can look for a normal form proof. One possible reference where you can read about this is Troelstra & Scwichtenberg’s “Basic Proof Theory” (I might have gotten the title wrong, but the authors are correct).
Hi Andrej,
Thanks for your PL zoo and your reply!
What I’m doing isn’t exactly a proof search in intuitionistic propositional logic in two ways: First, the stored coercions (non-logical axioms, if you’re thinking about it as a proof search) are allowed to have polymorphic types. Second, the interpreter doesn’t take the intuitionistic axioms for granted: for example, it won’t deduce the coercion
fst: ('a * 'b) -> 'aon its own. The only thing it tries are applications. (The second difference was mostly for my convenience.) Also, it doesn’t just look for a proof in normal form, it tries to make sure that it’s unique.But those are minor differences and you can indeed recast its search as a restricted intuitionistic proof search, although one which is undecidable since you have infinitely many non-logical axioms due to polymorphism.
I was originally thinking about having the compiler or interpreter infer an expression for a given type, and I first tried an intuitionistic proof search. This had a problem though, since when inferring a term with type
'a -> ('a * 'b -> 'a) -> 'b list -> 'a(which is intended to befold_left), a perfectly good intuitionistic proof would have you simply throw away all but the first argument and return that.Something that works, though, is to use linear logic instead of intuitionistic logic. You interpret , and let
, and let  is equivalent to
is equivalent to 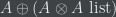 . Now, you have to require the programmer to annotate the type with
. Now, you have to require the programmer to annotate the type with  ‘s somehow, but under suitable hypotheses, there is only one proof of
‘s somehow, but under suitable hypotheses, there is only one proof of 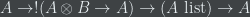 , and it corresponds under Curry-Howard to
, and it corresponds under Curry-Howard to  for linear implication since I’m not sure how to get the actual symbol.
for linear implication since I’m not sure how to get the actual symbol.
*aslistbe a constructor such thatfold_left, and similarly formap, etc. By the way, I’m usingThis currently seems impractical to me, though, for a couple of reasons, one of which is that the generated programs could easily be inefficient whereas if you have the user define coercions, they can make the functions as efficient as they like.
I see. Well, it’s a nice idea and you’ve clearly thought about it carefully. I would just add that having infinitely many axioms does not automagically give you undecidability. Your axioms are nicely structured (they are just parametrized by types), so possibly you can answer many interesting questions about them.
The idea with linear logic is neat. To circumvent the problem with guessing where the bangs should go, you could use relevant logic instead: it requires that every hypothesis be used at least once (programmers don’t write functions which accept useless arguments). This would also prevent a projection a*b->a from being deduced, although I am not sure whether this is good or bad. The trick then would be to find a proof which uses every hypothesis at least once, and as few times as possible. Can that give you anything interesting?
I think we talked about this over the Summer, but I never followed up. In any case, I’m very curious about the connection with linear logic. I have a bunch of questions…
It seems to me that you’re using intuitionistic linear logic. In particular, you probably don’t have an interpretation of “par” (distinct from ).
).
I can make sense of 1 as the empty list, do you have an interpretation for 0 (other than “fail”)?
Doesn’t the list constructor behave just like the exponential “!”? Wouldn’t it make sense to identify the two?
Andrej: I’ll have to look into relevant logic; I know nothing about it presently. In my current way of thinking, I do sometimes want to throw away a hypothesis (either to infer a projection (which I am, like you, not sure is a good thing to allow) or, for example, in the case of map where the list argument is empty you do not use the function argument), but that’s certainly not necessary and it’s quite possible relevant logic gives the framework I need.
François: I don’t have an interpretation for par, and it also turned out that I didn’t need . (This is in reference to my last comment; the posted compiler doesn’t use linear logic at all.) I don’t have interpretation for 0 (and, embarrassingly, I never really understood the distinction in linear logic either). The list constructor behaves a lot like ? (in that, if you have ?A as a resource, your opponent gets to choose how many A’s you have, and you can produce a ?A by bundling up as many A’s as you want), but I think that you can’t view the A’s you get from a ?A as coming with an order, although I could be wrong.
. (This is in reference to my last comment; the posted compiler doesn’t use linear logic at all.) I don’t have interpretation for 0 (and, embarrassingly, I never really understood the distinction in linear logic either). The list constructor behaves a lot like ? (in that, if you have ?A as a resource, your opponent gets to choose how many A’s you have, and you can produce a ?A by bundling up as many A’s as you want), but I think that you can’t view the A’s you get from a ?A as coming with an order, although I could be wrong.
In any case, I think that if you want to interpret constructors more general than “list”, it will not be easy to interpret them as exponentials.
I hope everything’s going great in Michigan!
Michigan is great! I’m having a good time in Ann Arbor.
The close connection with linear logic is starting to become clearer.
I think
&could be useful as an alternate product. You could then derive the projectionfst: ('a & 'b) -> 'aas well as the diagonaldiag: 'a -> ('a & 'a). The idea is that&is a “lazy” product, whereas*is an “eager” product.The same distinction applies to
!and?. They are both similar storage constructors, but!is “eager” while?is “lazy”. Lists make sense to me, but I can see that the implicit order could lead to problems. Some kind of reference types would also make sense, but I find this interpretation very sketchy and undesirable.As for the units, 1 is pretty clearly the empty list. I couldn’t make much sense of As for 0 and
As for 0 and 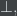 the axiom
the axiom  suggests that
suggests that 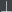 is “failure” and the axiom
is “failure” and the axiom  suggests that 0 is “void”. I don’t know if you really want partial functions, but
suggests that 0 is “void”. I don’t know if you really want partial functions, but 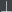 would be one way to explicitly allow for that. I don’t know if 0 is desirable, but I’m pretty confident it can’t hurt.
would be one way to explicitly allow for that. I don’t know if 0 is desirable, but I’m pretty confident it can’t hurt.
Of course, adding too many features will lead to undecidability. I wonder where the line is…
Using
&to get projections is a good idea. I had actually kind of stopped thinking about the linear logic side of things once I decided that it wouldn’t make for a practical implementation, but now that it’s come up again, it seems theoretically quite interesting to me.I’m not sure if using
&to get the diagonal function would work out though: if you used the diagonal function to get ana&afrom ana, you would probably want to use botha‘s (since otherwise, why did you apply the diagonal function in the first place?), but you can’t, by the definition of&.