By “voting”, I mean the following general problem: Suppose there are 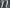

Observation #1 (which I read in Chapter 23 of David Easley and Jon Kleinberg’s book Networks, Crowds, and Markets): Voters will vote strategically (i.e., they will lie) even when they have a common goal.
In the setup above where each voter has a set of personal preferences and voters are essentially competing with other voters who have different preferences, it is easy to come up with situations where it would be advantageous for a voter to lie. For example, if a voter’s true rankings are 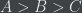


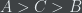
However, in a situation where every voter has the same goals, but they have different private information (and it’s impossible or infeasible for them to share their private information with each other), it seems like there’s never a reason for a voter to lie. But there is, even when there are only two alternatives that are being voted on.
Consider the following game: There is a vase filled with marbles. Either it has 10 white marbles (call this state
As you can work out: if you draw a white marble, you believe state 



However, voters will not vote their true beliefs: Suppose they did, and consider whether a fixed voter has an incentive to deviate from this strategy (i.e., consider whether all voters voting their true beliefs is a Nash equilibrium). When you draw a green marble, you should definitely vote for state
In the Easley-Kleinberg chapter, the authors also demonstrate a version of this with juries, where the vote must be unanimous to convict a defendant, and otherwise she will be acquitted. A similar situation happens: assume that you are thinking of voting to acquit. Under what circumstances will your vote make a difference? Only when every other juror has voted to convict. In that circumstance, it is quite likely that you are wrong, and the defendant was guilty, and thus you should have voted to convict no matter what! (This shows that everyone voting sincerely is not an equilibrium but doesn’t show what the equilibria of this game are. According to the authors, finding the equilibria is quite difficult.)
Observation #2 (which I saw in a paper by Roger Sewell, David Mackay, and Ian McLean): Maximizing the Entropy of the Outcome of Voting Leads to Good Results
As I alluded to above, Arrow’s impossibility theorem says that there’s no satisfactory way to provide an output ranking of candidates given the input rankings from each voter (here we will assume that we simply know each voter’s true ranking and not consider strategic voting). However, this just applies to deterministic voting procedures: it is, in fact, quite easy to come up with a probabilistic voting procedure satisfying all of the hypotheses of Arrow’s impossibility theorem: just pick a voter uniformly at random and take their preferences to be the output ranking!
Aside from the fact that it seems unlikely that the general public would accept such explicit randomization in the voting procedure any time soon, this process (which is called Random Dictator) has a couple of other negative aspects. First of all, it can easily lead to extreme outcomes: Suppose that there are 20 candidates, and the top 10 in the output ranking will be given various positions in the government. Suppose 10 candidates are from one political party, and 10 are from the other, and further that the populace is highly polarized: everyone ranks their party’s 10 candidates strictly better than each of the 10 candidates of the other party. Then it is guaranteed that a single-party government will be the result. What might be better is 10 officials chosen from a mix of the two parties according to each party’s representation in the voting public.
Another way in which Random Dictator doesn’t compromise very well is the following: Suppose there is heavy contention between candidates 
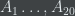
The authors of the paper fix these problems by proposing the following procedure: For each pair of candidates 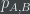
I won’t define maximum entropy here, but I will give a few examples. The idea that there is a number called the entropy associated with every probability distribution, and furthermore that if you are looking for a probability distribution in a certain class, but don’t know anything about it except that it is in that class, then the “right” distribution to take is the one that maximizes the entropy (obviously this is an unprovable assertion). In some sense, choosing the maximum entropy distribution from a class codifies the fact that you know nothing about it except that it is in that class.
For example, the maximum entropy probability distribution over the set 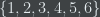
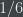


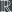
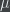
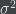
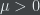
Basically, what the authors have proposed is that the actual total ranking of each voter are not important (or else we would have the first problem mentioned above), and in particular which candidate each voter happened to place in the top rank is not important (or else we would have the second problem mentioned above); the only thing that’s really important is getting the correct proportions of the pairwise rankings right. And the way to get a distribution on output rankings which reflects nothing except for the constraints on the pairwise rankings is to pick the maximum entropy distribution satisfying those constraints.
The beauty of this is that if you disagree with them, that’s fine: all you have to do is figure out what you think is the important information to preserve from the voters’ rankings, then pick the output distribution which maximizes entropy among those satisfying those rankings, and that will be the “right” output for your choice of what’s important, in the sense that it will not “take into account” anything that you don’t think is important. To take a trivial example, if you decide that the total ranking of each voter is important, then the maximum entropy distribution on output rankings will degenerate into the Random Dictator process.
The authors additionally ran simulations of elections using various voting procedures in order to verify that the maximum entropy voting scheme they propose is “better” (in some senses they define) than others.

I enjoyed that, thanks.
I second that!
Thanks guys!
I love this post, especially the second part.
For the first one, what would happen if each voter is allowed to produce a partial ordering of the candidates instead of a total ordering?
Very cool stuff! I might make my Math & Politics class read it.