The Strong Law of Small Numbers (see also Wikipedia) says that “There aren’t enough small numbers to meet the many demands made of them.” It means that when you look at small numbers, it’s easy to see compelling patterns that turn out to be false when you look at larger numbers.
Using complexity theory, we can give a partial account of this phenomenon. The concept that we’ll use is length-conditional complexity: if  is an
is an 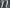 -bit number,
-bit number, 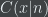 means the length of the shortest Turing machine that outputs when given as an input. In a previous post, I stated the following theorem:
means the length of the shortest Turing machine that outputs when given as an input. In a previous post, I stated the following theorem:
Theorem: Suppose you have a computable property 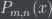 of -bit numbers such that:
of -bit numbers such that:
- For all
 , , ,
, , ,  implies
implies  .
.
- For all
 , , there are at least
, , there are at least  -digit numbers such that holds.
-digit numbers such that holds.
Then there is a  such that for all and , holds for every of length such that
such that for all and , holds for every of length such that 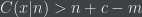 .
.
Furthermore, the number of ‘s of length such that is at least 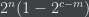 .
.
In this context,  might be of the form “ is not close to some special set of numbers”, like “ is not close to a square number” or “ is not close to a prime”, where the meaning of “close” will depend on and . Or it could be that some statistic about deviates from the expected value by some large amount (again, with the meaning of “large” depending on and ).
might be of the form “ is not close to some special set of numbers”, like “ is not close to a square number” or “ is not close to a prime”, where the meaning of “close” will depend on and . Or it could be that some statistic about deviates from the expected value by some large amount (again, with the meaning of “large” depending on and ).
Now, suppose we have a bag of computable properties  that we’re interested in. Assume that we’re using the same and for each and that they are of similar complexity, meaning that the value of in the above theorem is the same for each of them.
that we’re interested in. Assume that we’re using the same and for each and that they are of similar complexity, meaning that the value of in the above theorem is the same for each of them.
Then assuming that 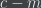 is small, given a random -bit number , it is likely (with probability at least
is small, given a random -bit number , it is likely (with probability at least  ) that satisfies , and thus
) that satisfies , and thus  should hold for all
should hold for all  without exception. If some doesn’t hold, that means some assumption was violated, in particular that
without exception. If some doesn’t hold, that means some assumption was violated, in particular that 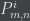 doesn’t hold for at least
doesn’t hold for at least  -bit numbers, which is good evidence that there’s some pattern or mathematical law here that you were unaware of (e.g., a large proportion of numbers are close to one in some special set). (Note that it is also possible that the assumption that was violated was that the complexity of was higher than expected. However, that is tied pretty closely to the length of a program that implements
-bit numbers, which is good evidence that there’s some pattern or mathematical law here that you were unaware of (e.g., a large proportion of numbers are close to one in some special set). (Note that it is also possible that the assumption that was violated was that the complexity of was higher than expected. However, that is tied pretty closely to the length of a program that implements 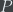 , so, assuming that you know how to compute , it’s unlikely that it’s much more complex than you originally thought.)
, so, assuming that you know how to compute , it’s unlikely that it’s much more complex than you originally thought.)
On the other hand, if is large (say,  ), then there may be no ‘s such that . In that case, it may simply be that the properties are independent for different values of
), then there may be no ‘s such that . In that case, it may simply be that the properties are independent for different values of 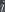 . In that case, it’s not reasonable to assume that if some fails, then you
. In that case, it’s not reasonable to assume that if some fails, then you
have discovered a possible new mathematical law, it may just be a coincidence instead.
Furthermore, as gets smaller, you will be forced to decrease , making larger, since if  , then each must be trivial, since it must hold of at least
, then each must be trivial, since it must hold of at least  of the
of the  numbers, and the only way to do that is to hold for all of them, making the properties trivial.
numbers, and the only way to do that is to hold for all of them, making the properties trivial.
I certainly don’t claim this captures everything about the Strong Law of Small Numbers. But I like this account, because it gives a way to think about what “small” means: namely, it means small enough that you’ve chosen an such that 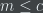 , where is the complexity of the properties of numbers that you’re interested in.
, where is the complexity of the properties of numbers that you’re interested in.
